
 Pentru a ajuta utilizatorii să comunice mai eficient în prezent și să facă parte din metaversul de mâine, cercetătorii Meta AI au creat No Language Left Behind (NLLB), un efort de a dezvolta capacități de traducere automată de înaltă calitate pentru majoritatea limbilor lumii.
Pentru a ajuta utilizatorii să comunice mai eficient în prezent și să facă parte din metaversul de mâine, cercetătorii Meta AI au creat No Language Left Behind (NLLB), un efort de a dezvolta capacități de traducere automată de înaltă calitate pentru majoritatea limbilor lumii.
• Meta AI a creat primul model AI, NLLB-200 care traduce în 200 de limbi la cea mai înaltă calitate, validat prin evaluări complexe pentru fiecare dintre acestea.
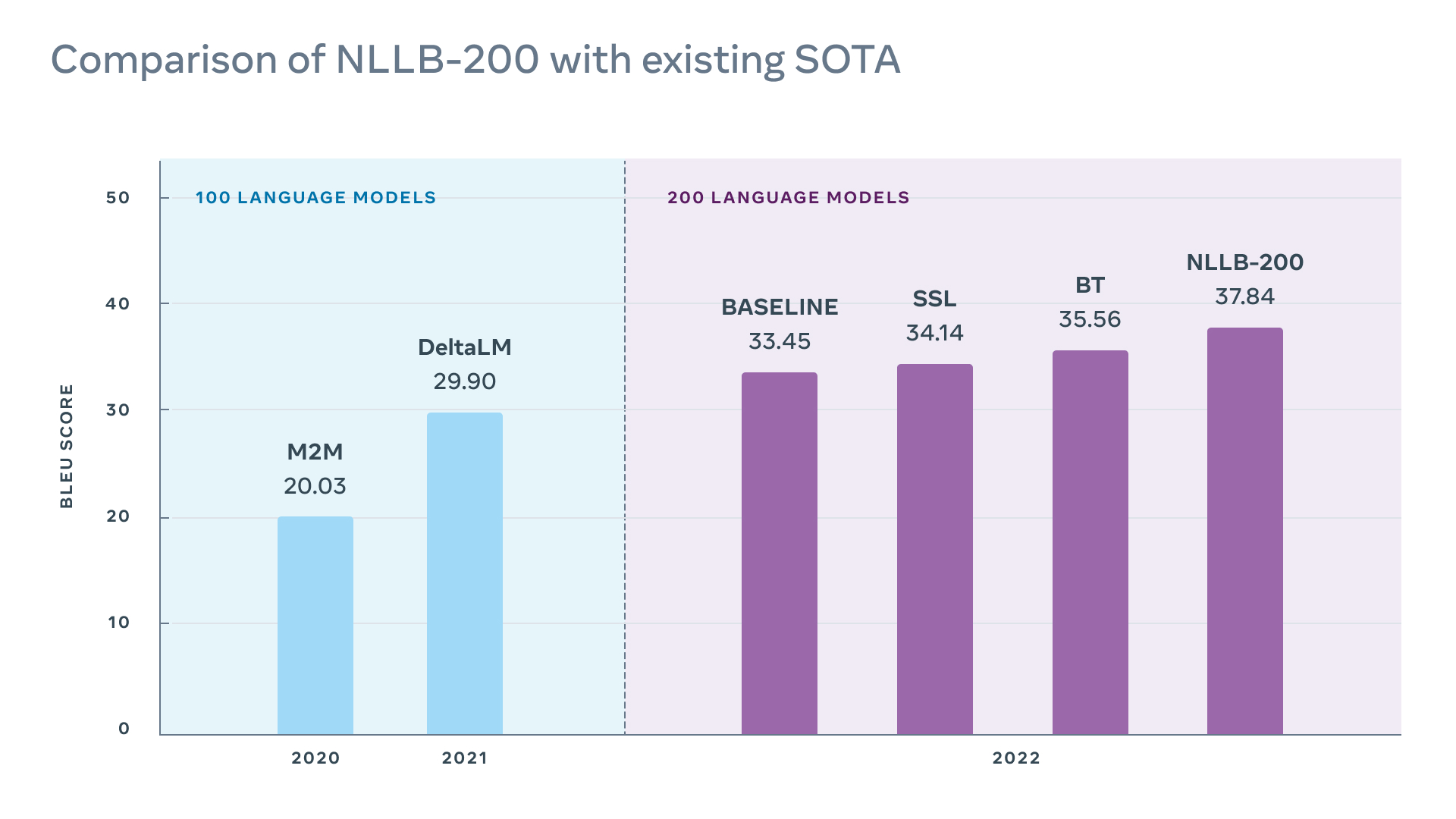
• În plus, compania a creat un nou set de date pentru evaluare, FLORES-200, și a măsurat performanța modelului NLLB-200 în fiecare limbă pentru a se asigura că traducerile sunt de calitate. NLLB-200 depășește în medie cu 44% soluția din generația precedentă.
• Acum utilizează tehnici de modelare și informații din proiect pentru a îmbunătăți și a extinde traducerile automate pe Facebook, Instagram și chiar pe Wikipedia.
• Modele NLLB-200, FLORES-200, cod pentru instruirea modelelor și cod pentru recrearea setului de date pentru instruire, vor fi puse în sistem open-source la dispoziția altor cercetători pentru ca aceștia să le poată valorifica și să își îmbunătățească instrumentele de traducere.
Limba reprezintă cultura, identitatea și legătura noastră cu lumea. Dar pentru că nu există instrumente de traducere de înaltă calitate pentru sute de limbi, miliarde de persoane nu au în prezent acces la conținut digital sau nu pot participa pe deplin la conversații în cadrul comunităților online în limbile lor preferate sau materne. Acest lucru este valabil mai ales pentru sute de milioane de persoane care vorbesc numeroasele limbi din Africa și Asia.
Astăzi anunțăm o inovație importantă în NLLB: am creat un model AI numit NLLB-200, care traduce în 200 de limbi cu rezultate de cea mai bună calitate. Multe dintre aceste limbi, cum ar fi kamba și lao, nu erau complet sau deloc compatibile nici cu cele mai bune instrumente de traducere existente. Mai puțin de 25 de limbi africane sunt în prezent acceptate de instrumente de traducere folosite la scară largă, dintre care multe au rezultate de slabă calitate. Însă NLLB-200 acceptă 55 de limbi africane cu rezultate de calitate înaltă. Acest model poate asigura traduceri de calitate pentru limbi vorbite de miliarde de oameni de pe tot globul. În total, scorurile BLEU ale modelului NLLB-200 sunt în medie cu 44% mai bune decât soluția din generația precedentă pentru toate cele 10 mii de direcții ale benchmarkului FLORES-101. În cazul unor limbi din Africa și India, rezultatele sunt cu peste 70% mai bune decât cele ale sistemelor de traducere recente.
Acum oferim modelul NLLB-200 în regim open source și publicăm mai multe instrumente de cercetare pentru a le permite altor cercetători să extindă aceste eforturi în mai multe limbi și să dezvolte tehnologii mai incluzive. În plus, Meta AI le oferă subvenții în valoare de până la 200.000 USD organizațiilor non-profit pentru utilizarea în lumea reală a modelului NLLB-200.
 Progresele înregistrate în cercetarea NLLB vor susține peste 25 de miliarde de traduceri difuzate în fiecare zi în Noutăți Facebook, pe Instagram și pe celelalte platforme ale noastre. Imaginează-ți că vizitezi unul dintre grupurile tale de Facebook preferate, găsești o postare în igbo sau luganda și poți să o afișezi în limba ta prin simpla apăsare a unui buton. Traducerile extrem de precise în mai multe limbi pot, de asemenea, să contribuie la identificarea conținutului dăunător și a informațiilor greșite, la protejarea integrității procesului electoral și la reducerea cazurilor de exploatare sexuală și trafic de persoane online. Tehnicile de modelare și informațiile din cercetările noastre bazate pe NLLB sunt aplicate acum și în sistemele de traducere utilizate de editorii Wikipedia.
Progresele înregistrate în cercetarea NLLB vor susține peste 25 de miliarde de traduceri difuzate în fiecare zi în Noutăți Facebook, pe Instagram și pe celelalte platforme ale noastre. Imaginează-ți că vizitezi unul dintre grupurile tale de Facebook preferate, găsești o postare în igbo sau luganda și poți să o afișezi în limba ta prin simpla apăsare a unui buton. Traducerile extrem de precise în mai multe limbi pot, de asemenea, să contribuie la identificarea conținutului dăunător și a informațiilor greșite, la protejarea integrității procesului electoral și la reducerea cazurilor de exploatare sexuală și trafic de persoane online. Tehnicile de modelare și informațiile din cercetările noastre bazate pe NLLB sunt aplicate acum și în sistemele de traducere utilizate de editorii Wikipedia.
Traducerea este unul dintre cele mai interesante domenii în care se utilizează AI, datorită impactului său asupra vieții noastre cotidiene. NLLB înseamnă mult mai mult decât îmbunătățirea accesului utilizatorilor la conținutul de pe web. Acesta va ajuta persoanele să contribuie la și să distribuie informații în diverse limbi. Mai avem mult de lucru, dar suntem stimulați de progresele noastre recente și de modul în care acestea ne aduc mai aproape de îndeplinirea misiunii Meta.
Poți să urmărești o demonstrație pentru NLLB-200 aici, în care se prezintă cum modelul poate să traducă postări din întreaga lume sau să citești studiul aici.
Punerea instrumentelor de traducere la dispoziția a miliarde de persoane
Am încheiat un parteneriat cu Wikimedia Foundation, organizația non-profit care găzduiește Wikipedia și alte proiecte cu informații gratuite, pentru a contribui la îmbunătățirea sistemelor de traducere de pe Wikipedia. Există versiuni ale platformei Wikipedia în peste 300 de limbi, dar majoritatea au mult mai puține articole decât cele peste 6 milioane disponibile în engleză. Această discrepanță este mare mai ales pentru limbile vorbite în principal în afara Europei și a Americii de Nord. De exemplu, există aproximativ 3.260 de articole Wikipedia în lingala, o limbă vorbită de 45 de milioane de persoane în Republica Democrată Congo, Republica Congo, Republica Centrafricană și Sudanul de Sud. Compară această cifră cu o limbă precum suedeza, care are 10 milioane de vorbitori în Suedia și Finlanda și peste 2,5 milioane de articole.
Editorii Wikipedia folosesc acum tehnologia pe care se bazează NLLB-200, prin intermediul instrumentului de traducere a conținutului de la Wikimedia Foundation, pentru a traduce articole în peste 20 de limbi cu resurse reduse (cele care nu au seturi de date mari pentru instruirea sistemelor AI), inclusiv 10 care nu erau acceptate în trecut de niciun instrument de traducere automată de pe platformă.
Provocările dezvoltării unui singur model pentru sute de limbi
Sistemele de traducere automată, cum sunt toate modelele AI, sunt instruite cu ajutorul datelor. În cazul sistemelor de traducere a textului, procesul constă de obicei în milioane de propoziții corelate atent între limbi. Dar nu există volume mari de propoziții echivalente, de exemplu, între engleză și fula. Modelele de traducere actuale încearcă să rezolve această problemă prin extragerea datelor de pe web. Dar rezultatele sunt adesea de slabă calitate deoarece textul sursă este diferit pentru fiecare limbă. În plus, este adesea plin de cuvinte ortografiate incorect și inconsecvent și îi lipsesc semnele de accentuare și alte semne diacritice.
O altă provocare majoră o reprezintă optimizarea unui singur model pentru a funcționa în sute de limbi fără a compromite performanța sau calitatea traducerii. De obicei, calitatea optimă a traducerii se obține folosind un model separat pentru fiecare direcție de scriere a limbii respective. Dar această abordare este greu de adaptat, deoarece performanța și calitatea traducerii sunt afectate pe măsură ce sunt adăugate mai multe limbi.
În plus, modelele de traducere cauzează erori care pot fi dificil de detectat. Aceste sisteme se bazează pe rețele neuronale folosite pentru generarea textului, prin urmare pot cauza în mod normal erori cum ar fi halucinațiile (convingerea că ceva este adevărat, chiar dacă nu este), afirmațiile incorecte și conținutul nesigur. În general, sunt disponibile mai puține benchmarkuri și seturi de date pentru limbile cu resurse reduse, ceea ce face mult mai dificilă testarea și îmbunătățirea modelelor.
 Inovații în arhitectură, colectarea datelor, analiza comparativă și altele
Inovații în arhitectură, colectarea datelor, analiza comparativă și altele
În ultimii ani, am făcut progrese constante pentru a depăși provocările descrise mai sus. În 2020, am anunțat modelul de traducere M2M-100 în 100 de limbi, care utiliza noi metode de a obține date de instruire, arhitecturi noi pentru a scala dimensiunea modelului fără a compromite performanța și noi modalități de a evalua și îmbunătăți rezultatele. Pentru a-l scala pentru încă 100 de limbi, am făcut progrese în toate aceste trei privințe.
Resurse pentru instruire îmbunătățite
Pentru a colecta texte echivalente extrem de precise în mai multe limbi, am îmbunătățit LASER, kitul nostru de instrumente pentru transferul zero-shot în prelucrarea limbajului natural (NLP). În loc de LSTM, noua versiune, LASER3, utilizează un model Transformer care este instruit într-un mod auto-supravegheat, cu un obiectiv de modelare a limbajului mascat. Am îmbunătățit performanța folosind o procedură de instruire de tip profesor-elev și creând codificatoare specifice grupurilor de limbi, ceea ce ne-a permis să scalăm acoperirea limbilor pentru LASER3 și să generăm volume uriașe de perechi de propoziții, chiar și pentru limbile cu resurse reduse. Oferim în regim open source metoda de încorporare a mai multor limbi LASER3 pentru a o pune la dispoziția altor cercetători și facem disponibile miliarde de propoziții echivalente în diferite perechi de limbi, care au fost extrase și filtrate folosind tehnicile descrise aici.
Întrucât am luat în calcul mai multe opțiuni atunci când am colectat exemple de instruire în mai multe limbi, era important să asigurăm calitatea exemplelor. Am refăcut complet pipeline-ul de filtrare a datelor pentru a-l scala la 200 de limbi, adăugând etape de filtrare importante care presupuneau mai întâi utilizarea modelelor LID-200 pentru a filtra date și a elimina zgomotul din corpusurile de pe internet cu un nivel ridicat de încredere. Am creat liste de toxicitate pentru întregul set de 200 de limbi, apoi am folosit listele respective pentru a evalua și a filtra potențiala toxicitate halucinatorie. Prin aceste etape, ne-am asigurat că avem seturi de date mai curate și mai puțin toxice, cu limbi identificate corect. Acest aspect este important pentru îmbunătățirea calității traducerii și reducerea riscului toxicității halucinatorii, unde sistemul introduce din greșeală conținut toxic în timpul procesului de traducere.














