
Până acum, traducerea AI s-a concentrat pe limbile scrise. Cu toate acestea, dintre cele peste 7.000 de limbi vorbite, mai mult de 40% dintre ele sunt în principal orale și nu au un standard sau un sistem de scriere larg cunoscut. Proiectul Universal Speech Translator (UST) al Meta se concentrează pe dezvoltarea sistemelor AI care oferă traducerea vorbirii în timp real în toate limbile, chiar și în cele vorbite preponderent.
 Abilitatea de a vorbi cu oamenii în diferite limbi, fără a fi necesari ani de studiu, este un vis căutat de mult timp. Comunicarea verbală poate ajuta la înlăturarea barierelor și la unirea oamenilor oriunde s-ar afla – chiar și în Metaverse. Am făcut un pas către atingerea acestui obiectiv prin UST, primul sistem de traducere a vorbirii alimentat de inteligență artificială (AI)
Abilitatea de a vorbi cu oamenii în diferite limbi, fără a fi necesari ani de studiu, este un vis căutat de mult timp. Comunicarea verbală poate ajuta la înlăturarea barierelor și la unirea oamenilor oriunde s-ar afla – chiar și în Metaverse. Am făcut un pas către atingerea acestui obiectiv prin UST, primul sistem de traducere a vorbirii alimentat de inteligență artificială (AI)
dezvoltat pentru o limbă nescrisă.
După cum am menționat la evenimentul Meta Connect de luna aceasta, cercetătorii noștri AI au construit și au folosit sisteme de traducere open-source pentru hokkien, care este una dintre limbile oficiale ale Taiwanului și este vorbită pe scară largă de către diaspora chineză, dar nu are o formă scrisă standard. Această tehnologie permite vorbitorilor dialectului
hokkien să poarte conversații cu oameni care vorbesc engleza.
Depășirea provocărilor datelor
Colectarea de date a fost un obstacol semnificativ cu care ne-am confruntat atunci când ne-am propus să construim un sistem de traducere a hokkien. Hokkien este ceea ce este cunoscut ca un limbaj cu resurse insuficiente, ceea ce înseamnă că nu există o sursă amplă de date pentru instruire disponibile, în comparație cu, să zicem, spaniola sau engleza. În plus, există relativ puțini traducători umani care sa poată traduce din engleză în hokkien, ceea ce face dificilă colectarea și adnotarea de date pentru antrenarea modelului.
Ca limbă intermediară, am folosit mandarina pentru a construi pseudo-etichete, și am tradus prima dată vorbirea în engleză (sau hokkien) în text în mandarină, apoi am tradus în hokkien (sau engleză) și am adăugat în datele de antrenament. Această metodă a îmbunătățit foarte mult performanța modelului prin valorificarea datelor unei limbi similare cu resurse ridicate.
Examinarea discursului este o altă abordare a creșterii datelor de instruire. Cu un codificator de vorbire performant, suntem capabili să codificăm incluziunile vocale hokkien în același spațiu semantic ca și textul în limba engleză. Discursul hokkien ar putea fi aliniat cu textele în engleză ale căror structuri semantice sunt asemănătoare. Sintetizăm în continuare vorbirea în engleză din texte, obținând vorbire paralelă în hokkien și engleză.
O nouă abordare
Multe sisteme de traducere a vorbirii se bazează pe transcrieri sau sunt sisteme de traducere a vorbirii în text, dar limbile nescrise nu au forme scrise standard. Aceasta înseamnă că producerea de text transcris după traducere nu este logică. Astfel, ne concentrăm pe traducerea vorbirii în timp real.
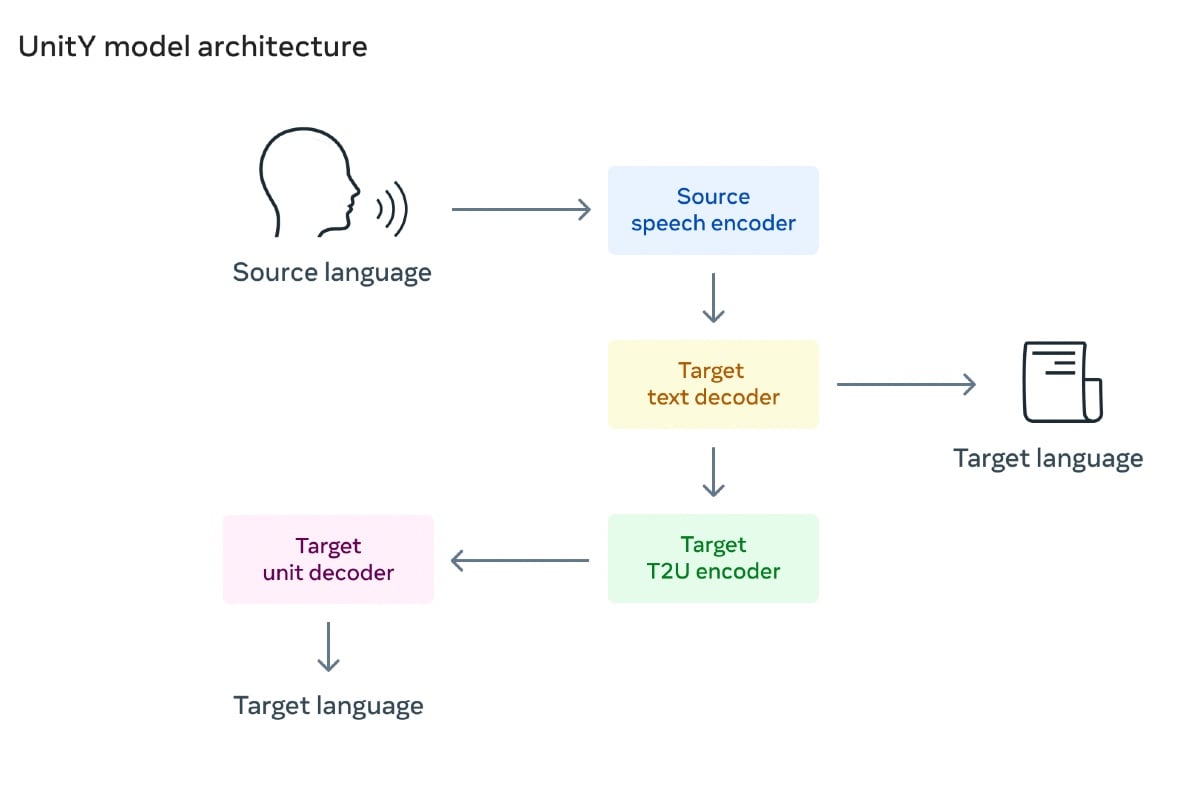
Proiectul nostru a necesitat o abordare diversă. Am folosit traducerea speech-to-unit (S2UT) pentru a converti vorbirea într-o secvență de unități acustice, având ca bază cercetările anterioare ale Meta. Atunci unitățile au generat noi forme de undă. În plus, UnitY a fost adoptat ca mecanism în două treceri, în care primul decodor generează textul într-o limbă înrudită (mandarina) și al doilea creează unități.
Evaluarea traducerilor Hokkien
Sistemele de traducere a vorbirii sunt, adeseori, evaluate utilizând măsura metrică numită ASR-BLEU, ce implică mai întâi transcrierea discursului tradus în text, cu ajutorul sistemului de recunoaștere automată a vorbirii (ASR), iar apoi calcularea scorului BLEU (o măsură standard de traducere automată) prin compararea textului transcris cu un text tradus de un om. Cu toate acestea, una din provocările legate de evaluarea traducerilor vocale pentru o limbă nescrisă, precum hokkien, este faptul că nu există un sistem de scriere standard.
Pentru a permire evaluarea automată, am dezvoltat un sistem ce transcrie vorbirea în hokkien într-un sistem de scriere fonetic standardizat, numit Tâi-lô. Acesta ne permite apoi să calculăm un scor BLEU la nivel de silabă și să comparăm cu ușurință calitatea traducerii în diferite abordări.
Pe lângă dezvoltarea unei metode de evaluare a traducerilor vocale hokkien-engleză, am creat și primul set de date de referință pentru traducerea bidirecțională hokkien-engleză, din vorbire, bazat pe o culegere de vorbire hokkien, numită Taiwanese Across Taiwan. Acest set de date de referință va fi oferit în sistem open-source pentru a încuraja alți cercetători să
lucreze la traducerea vocală în hokkien pentru progrese suplimentare în acest domeniu.
Privind către viitorul traducerii
Plănuim să folosim sistemul nostru de traducere, în limba hokkien, ca parte a unui traducător universal și vom publica modelul, codul și datele noastre de instruire pentru comunitatea AI, pentru a permite altor cercetători să lucreze cu acest model. În faza sa actuală, abordarea noastră permite unei persoane care vorbește hokkien să poarte conversații cu cineva care vorbește engleză. În timp ce modelul este încă în curs de dezvoltare și poate traduce o singură propoziție pe rând, reprezintă un pas spre viitor în care traducerea simultană între limbi este posibilă.
Tehnicile pe care le-am introdus în cazul limbii Hokkien pot fi extinse către multe alte limbi nescrise și, în cele din urmă, vor funcționa în timp real. În acest scop, lansăm matricea de vorbire, o culegere mare de traduceri în dialoguri, obținute cu ajutorul tehnicii inovatoare de extragere a datelor a Meta, numită LASER, ce va permite cercetătorilor să-și creeze propriile
sisteme de traducere a vorbirii în timp real (S2ST).
Tehnica LASER transformă propozițiile din diferite limbi într-o singură reprezentare, multimodală și multilingvă. Am utilizat o similaritate multilingvă, la scară largă, pentru a identifica propozițiile ce sunt similare din punct de al spațiului semantic, adică care au probabilitatea de a avea același înțeles în limbi diferite. Am aplicat tehnica LASER pentru a construi CCMatrix și CCAligned, care sunt capabile să găsească texte paralele pe internet.
Recent, echipa noastră a extins LASER pentru a integra, de asemenea, și vorbirea. Prin crearea de reprezentări pentru vorbire și text, în același spațiu multilingvistic, putem extrage traduceri pentru vorbirea într-o limbă și textul din altă limbă – sau chiar traduceri directe din dialoguri. Datele extrase din Speech Matrix oferă un total de 418 mii de ore de vorbire paralelă, ce acoperă 272 de direcții lingvistice. Mai mult de 8,000 de ore de discurs în limba hokkien au fost extrase împreună cu traducerile corespunzătoare în limba engleză.
În plus, progresele recente înregistrate de Meta în domeniul recunoașterii neasistate a vorbirii (wav2vec-U) și a traducerii automate neasistate (mBART) vor contribui la traducerea mai multor limbi vorbite. Cu aceste progrese în învățarea neasistată, demonstrăm fezabilitatea construirii unor programe de înaltă calitate pentru traducerea vorbirii în timp real, fără adnotări umane.
Cercetarea în domeniul inteligenței artificiale ajută la eliminarea barierelor lingvistice, atât în lumea reală, cât și în Metaverse. În viitor, toate limbile, fie scrise sau nescrise, ar putea să nu mai fie un obstacol în calea înțelegerii reciproce. Așteptăm cu nerăbdare să contribuim la acest viitor al comunicării fără frontiere.














